
|
| Our method jointly reconstructs high fidelity two-hand meshes from multi-view RGB image. The input images shown here are from our synthetic dataset, which contains challenging video sequences of two hands rendered into egocentric views. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Our method jointly reconstructs high fidelity two-hand meshes from multi-view RGB image. The input images shown here are from our synthetic dataset, which contains challenging video sequences of two hands rendered into egocentric views. |
| We propose a novel transformer-based framework that reconstructs two high fidelity hands from multi-view RGB images. Unlike existing hand pose estimation methods, where one typically trains a deep network to regress hand model parameters from single RGB image, we consider a more challenging problem setting where we directly regress the absolute root poses of two-hands with extended forearm at high resolution from egocentric view. As existing datasets are either infeasible for egocentric viewpoints or lack background variations, we create a large-scale synthetic dataset with diverse scenarios and collect a real dataset from multi-calibrated camera setup to verify our proposed multi-view image feature fusion strategy. To make the reconstruction physically plausible, we propose two strategies: (i) a coarse-to-fine spectral graph convolution decoder to smoothen the meshes during upsampling and (ii) an optimisation-based refinement stage at inference to prevent self-penetrations. Through extensive quantitative and qualitative evaluations, we show that our framework is able to produce realistic two-hand reconstructions and demonstrate the generalisation of synthetic-trained models to real data, as well as real-time AR/VR applications. |
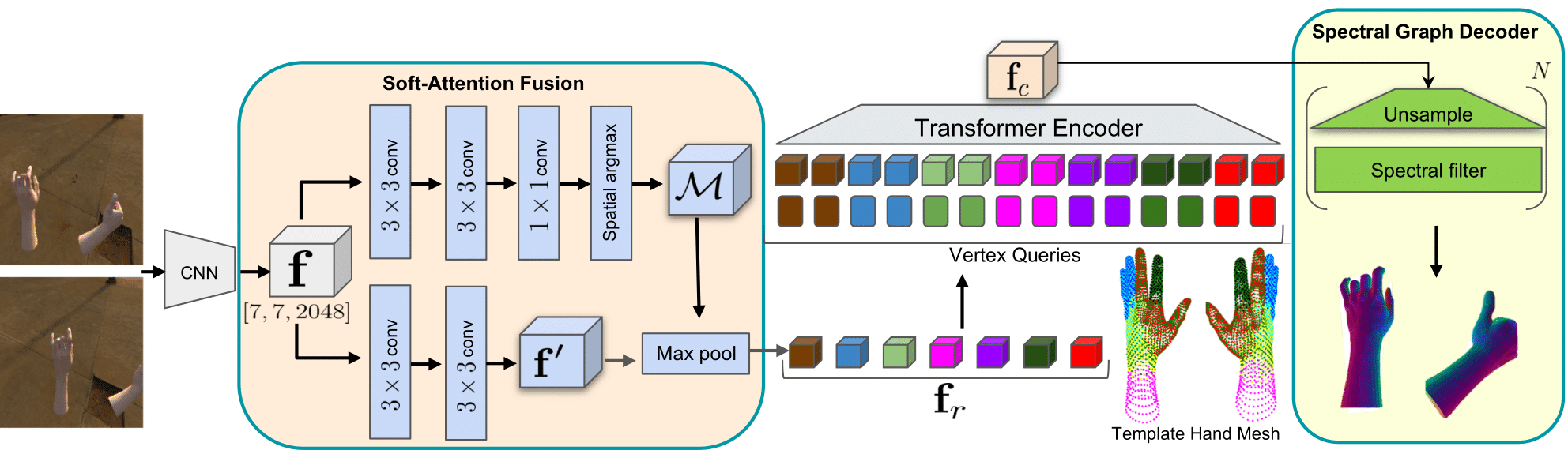 |
| A schematic illustration of our framework. Given multi-view RGB images, we extract volumetric features with a shared CNN backbone. The soft-attention fusion block generates the attention mask and finer image features through multiple upsampling and convolution blocks. Region-specific features are computed by first aggregating along the feature channel dimension via the attention mask, followed by a max-pooling operation across multi-view images to focus on useful features. Then, we apply mesh segmentation via spectral clustering on template hand meshes and uniformly subsample them to obtain coarse meshes. We perform position encoding by concatenating coarse template meshes to the corresponding region-specific features, i.e. matching colored features to mesh segments. Finally, our multi-layer transformer encoder takes the resulting features as input and outputs a coarse mesh representation which is then decoded by a spectral graph decoder to produce the final two-hand meshes at target resolution. Here, each hand contains 4023 vertices. |
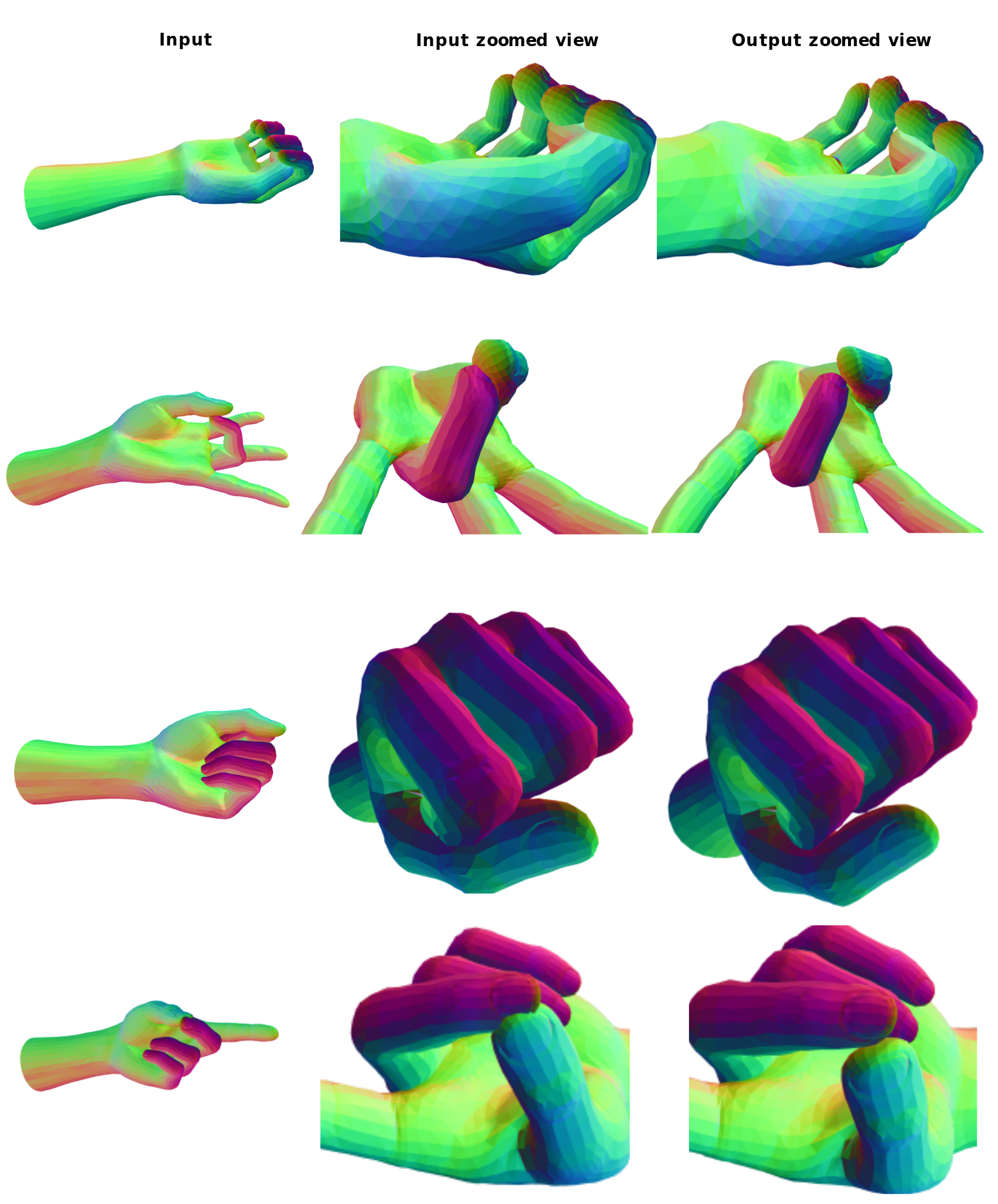 |
| Qualitative example of mesh refinement at inference. Our optimisation-based strategy shows robustness to various hand poses. |
 |
| Failure examples for mesh refinement when self-penetration is highly complex. |
 |
| Additional qualitative examples on our synthetic dataset. |
Acknowledgements |
