
Publications
Research
I’m broadly interested in computer vision and machine learning. Much of my research is about 3D vision, 3D human body modelling and robotics.
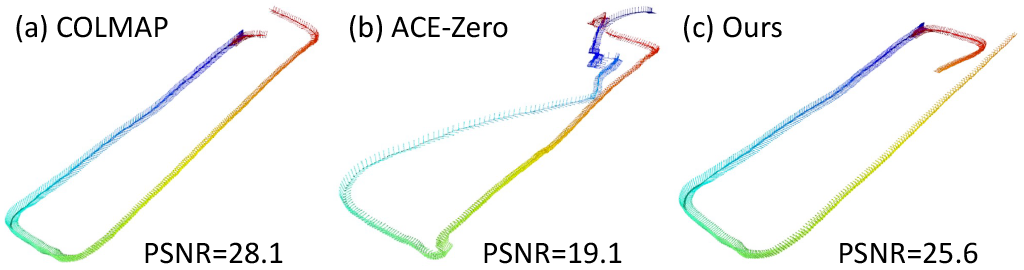 | Learning Scene Coordinate Reconstruction from Unposed Images via Pose Graph Optimization Tze Ho Elden Tse, Jizong Peng, Angela Yao CVPR, 2026 [Highlight] [pdf] [code] [webpage] We present a hybrid framework that integrates pose graph optimization (PGO) into ACE-Zero to refine camera poses and suppress incorrect refinements. |
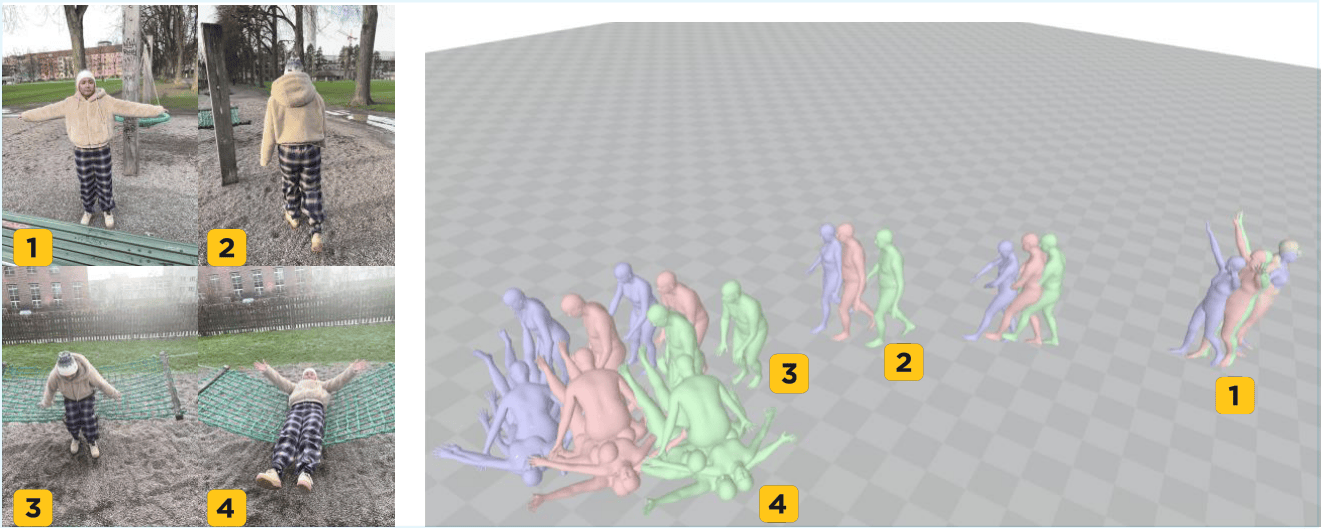 | HumanBA: Human-Aware Bundle Adjustment via Global Human-Camera Decoupling Fengyuan Yang, Tanuj Sur, Tze Ho Elden Tse, Angela Yao CVPR, 2026 [pdf] [code] [webpage] We present HumanBA, a human-aware bundle adjustment framework that transforms dynamic humans into usable constraints for global human recovery. |
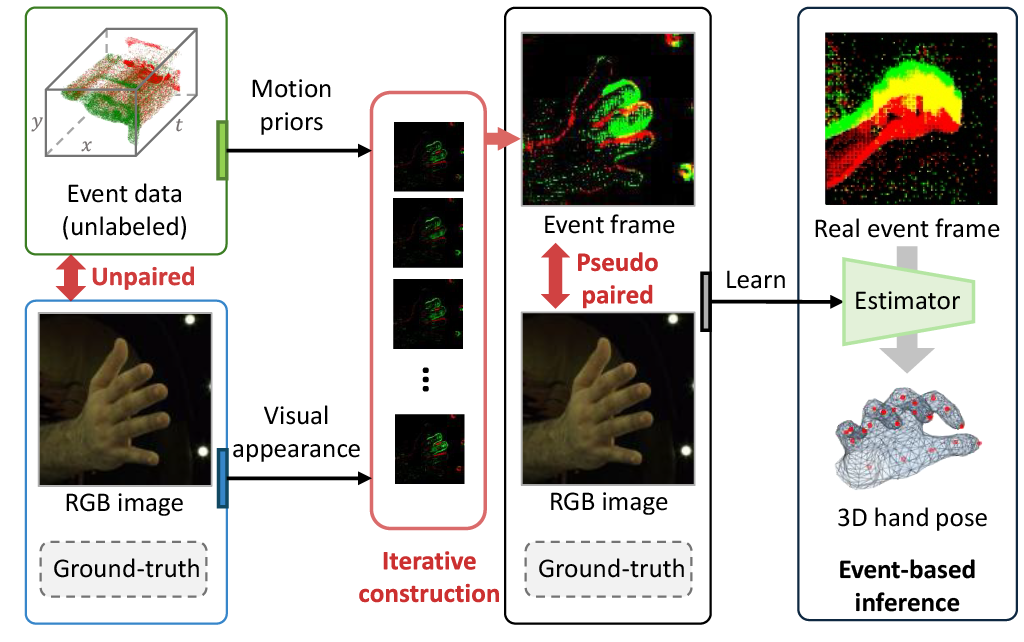 | Leveraging RGB Images for Pre-Training of Event-Based Hand Pose Estimation Ruicong Liu, Takehiko Ohkawa, Tze Ho Elden Tse, Mingfang Zhang, Angela Yao, Yoichi Sato ICCVW, 2025 [pdf] We present the first pre-training method for event-based 3D hand pose estimation using labeled RGB images and unpaired, unlabeled event data. |
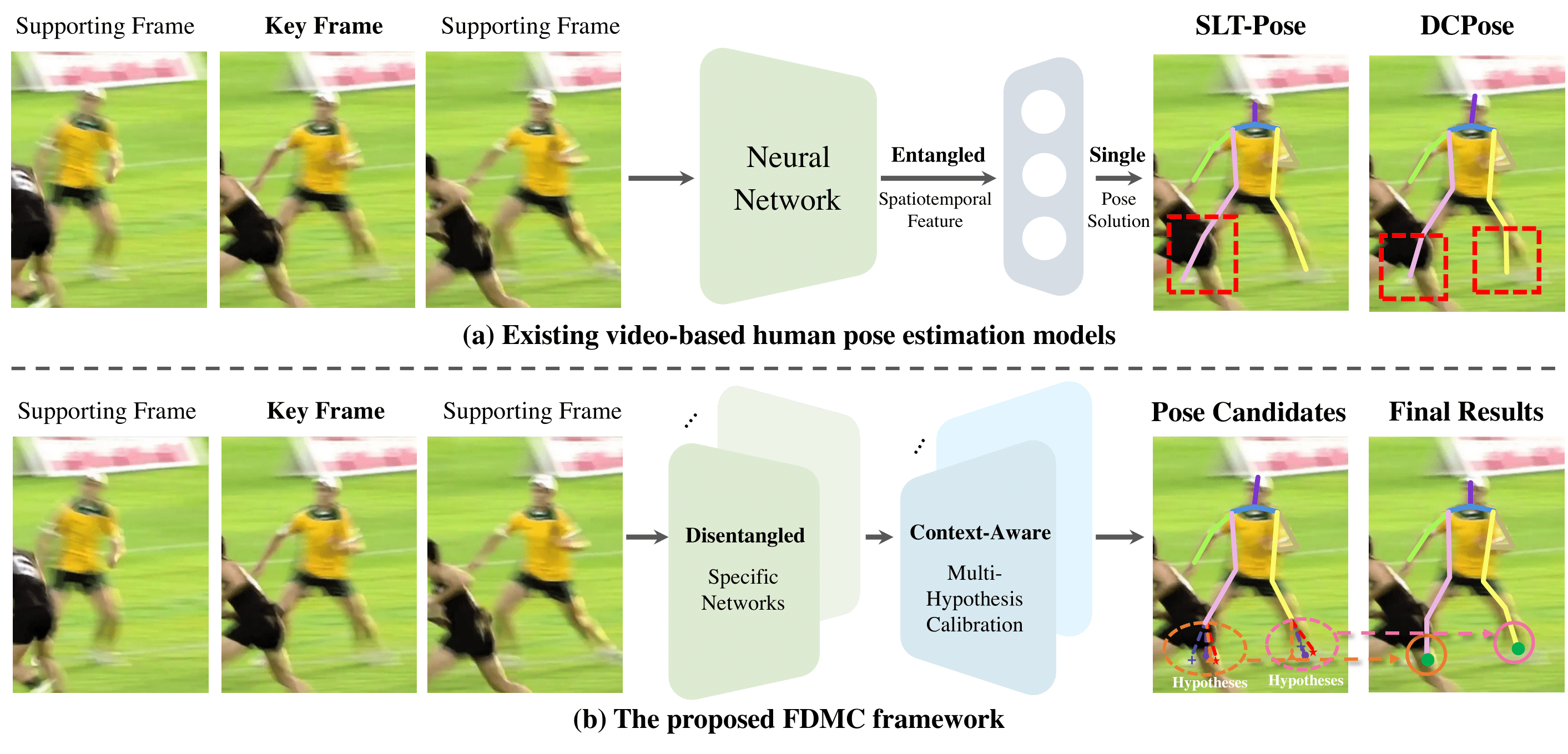 | Video-Based Human Pose Estimation via Feature Decoupling and Multi-Hypothesis Calibration Runyang Feng, Tze Ho Elden Tse, Haoming Chen, Hyung Jin Chang, Haifeng Zhong, Yixing Gao Pattern Recognition, 2025 [pdf] We propose a new framework which explores mutual information-based feature decomposition and context-aware multi-hypothesis calibration for video-based human pose estimation. |
 | Improving Human Motion Plausibility with Body Momentum Ha Linh Nguyen, Tze Ho Elden Tse, Angela Yao BMVC, 2025 [pdf] [code] [webpage] We propose to use whole-body linear and angular momentum as a constraint to link local motion with global movement for global human motion recovery. |
 | TIGeR: Text-Instructed Generation and Refinement for Template-Free Hand-Object Interaction Yiyao Huang, Zhedong Zheng, Ziwei Yu, Yaxiong Wang, Tze Ho Elden Tse, Angela Yao ICRA, 2026 [pdf] We propose a new Text-Instructed Generation and Refinement (TIGeR) framework for template-free hand and object reconstruction. |
 | Visual Intention Grounding for Egocentric Assistants Pengzhan Sun, Junbin Xiao, Tze Ho Elden Tse, Yicong Li, Arjun Akula, Angela Yao ICCV, 2025 [pdf] [dataset & code] [webpage] We introduce the first dataset, named EgoIntention, for egocentric visual intention grounding. We also propose Reason-to-Grounding (RoG) instruction tuning, a model-agnostic training approach to enhance MLLMs for egocentric intention grounding. |
 | A Constrained Optimization Approach for Gaussian Splatting from Coarsely-posed Images and Noisy Lidar Point Clouds Jizong Peng$^*$, Tze Ho Elden Tse$^*$, Kai Xu, Wenchao Gao, Angela Yao ICCV, 2025 [Highlight] [pdf] [code] [webpage] We present a contrained optimization approach for training Gaussian Splatting without COLMAP from multi-modal camera rig. |
 | DAS3R: Dynamics-Aware Gaussian Splatting for Static Scene Reconstruction Kai Xu, Tze Ho Elden Tse, Jizong Peng, Angela Yao arXiv, 2024 [pdf] [code] [webpage] We present a novel framework for scene decomposition and static background reconstruction from unposed videos. |
 | Humans as Checkerboards: Calibrating Camera Motion Scale for World-Coordinate Human Mesh Recovery Fengyuan Yang, Kerui Gu, Ha Linh Nguyen, Tze Ho Elden Tse, Angela Yao ICCV, 2025 [pdf] [code] [webpage] We present a simple but effective optimization-free scale calibration framework for global human motion recovery. |
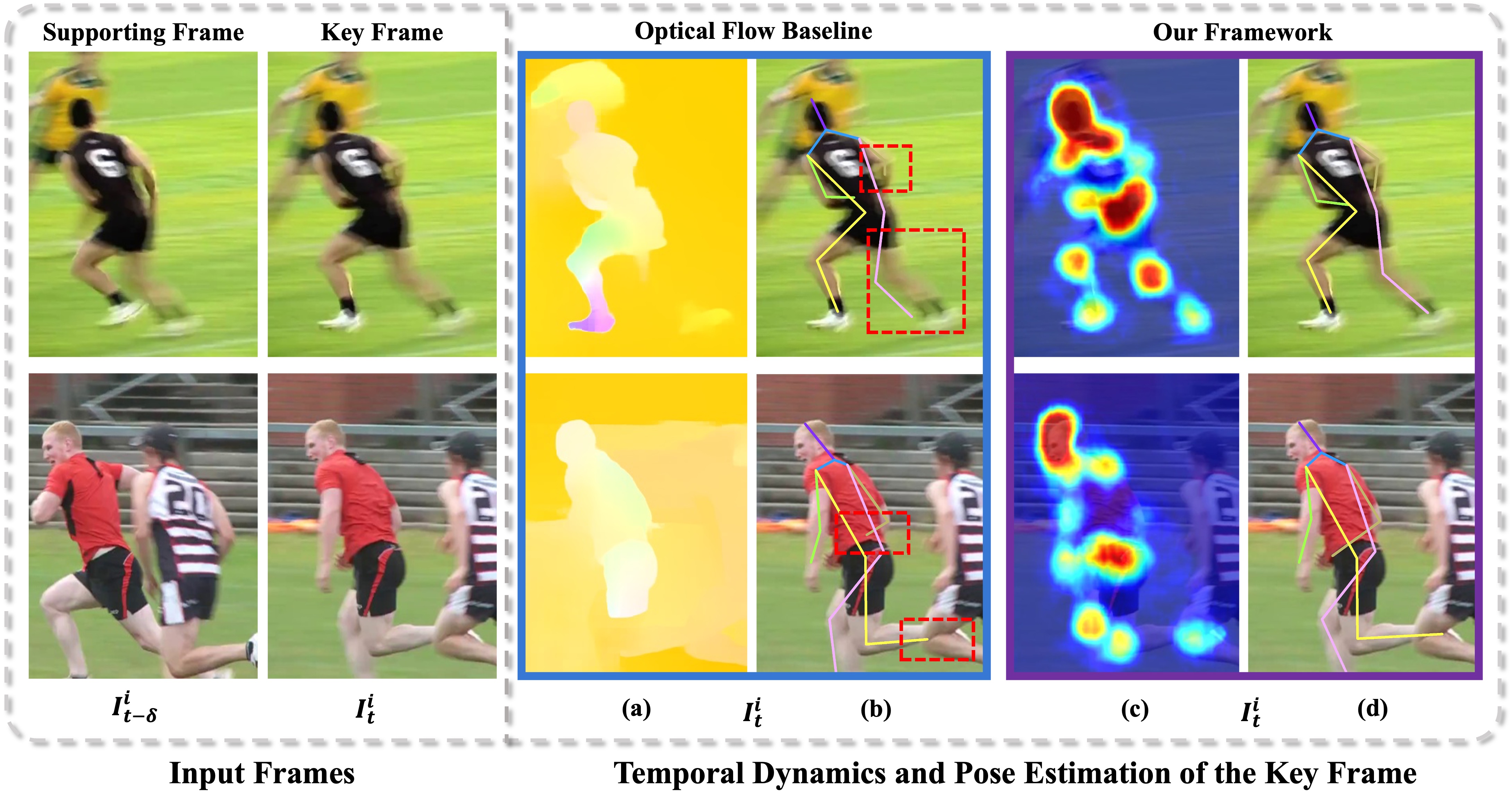
 | High-Resolution Spatiotemporal Modeling with Global-Local State Space Models for Video-Based Human Pose Estimation Runyang Feng, Hyung Jin Chang, Tze Ho Elden Tse, Boeun Kim, Yi Chang, Yixing Gao ICCV, 2025 [pdf] We propose a new VHPE framework that extends Mamba (state space model) for modelling high-resolution spatiotemporal representations. |
 | Collaborative Learning for 3D Hand-Object Reconstruction and Compositional Action Recognition from Egocentric RGB Videos Using Superquadrics Tze Ho Elden Tse, Runyang Feng, Linfang Zheng, Jiho Park, Yixing Gao, Jihie Kim, Ales Leonardis, Hyung Jin Chang AAAI, 2025 [pdf] We introduce a collaborative learning framework for 3D hand-object reconstruction and compositional action recognition using superquadrics. |
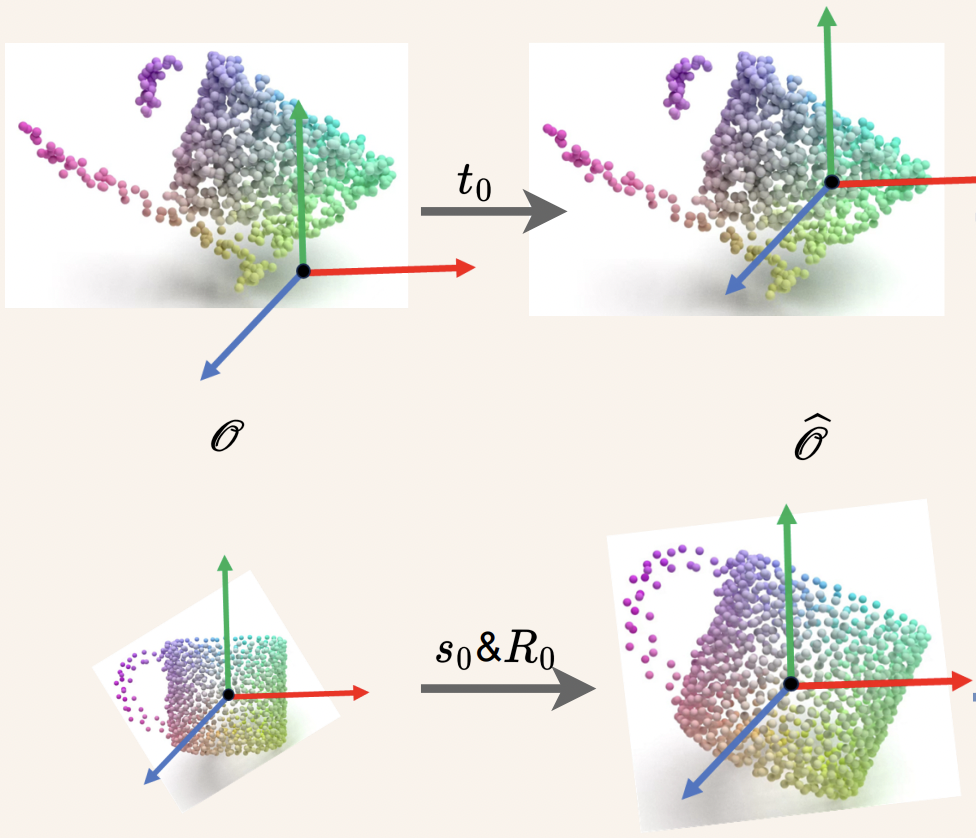 | GeoReF: Geometric Alignment Across Shape Variation for Category-level Object Pose Refinement Linfang Zheng, Tze Ho Elden Tse, Chen Wang, Yinghan Sun, Hua Chen, Ales Leonardis, Wei Zhang, Hyung Jin Chang CVPR, 2024 [pdf] [code] We introduce a novel framework for category-level object pose refinement which integrates an HS-layer and learnable affine transformations to enhance the extraction and alignment of geometric information. |
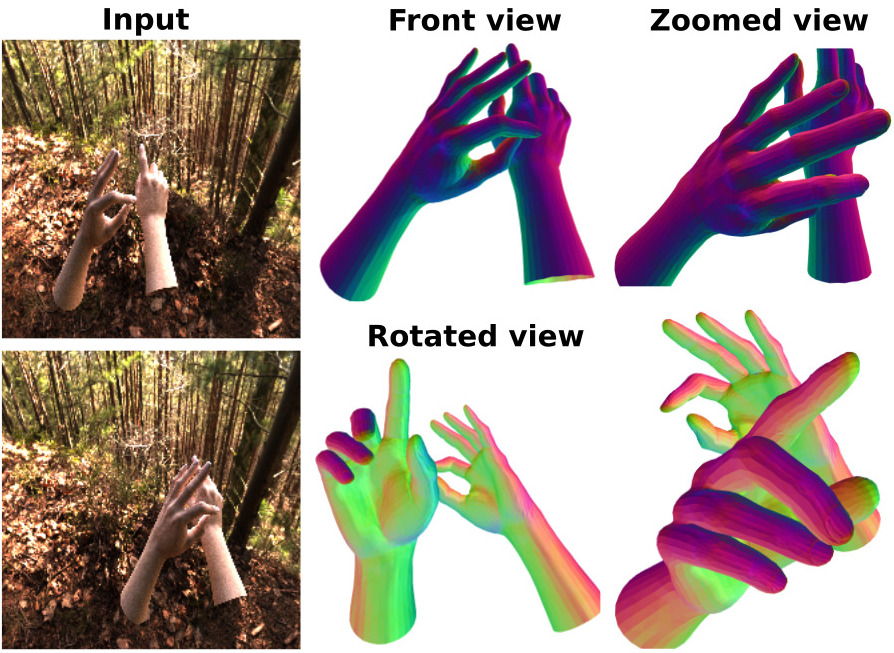 | Spectral Graphormer: Spectral Graph-based Transformer for Egocentric Two-Hand Reconstruction using Multi-View Color Images Tze Ho Elden Tse, Franziska Mueller, Zhengyang Shen, Danhang Tang, Thabo Beeler, Mingsong Dou, Yinda Zhang, Sasa Petrovic, Hyung Jin Chang, Jonathan Taylor, Bardia Doosti ICCV, 2023 [pdf] [webpage] [code] We present a spectral graph-based Transformer framework that reconstructs two high fidelity hands from multi-view RGB images. The proposed framework combines ideas from spectral graph theory and Transformers. |
 | DiffPose: SpatioTemporal Diffusion Model for Video-Based Human Pose Estimation Runyang Feng, Yixing Gao, Tze Ho Elden Tse, Xueqing Ma, Hyung Jin Chang ICCV, 2023 [pdf] [webpage] We present a diffusion architecture that formulates video-based human pose estimation as a conditional heatmap generation problem. |
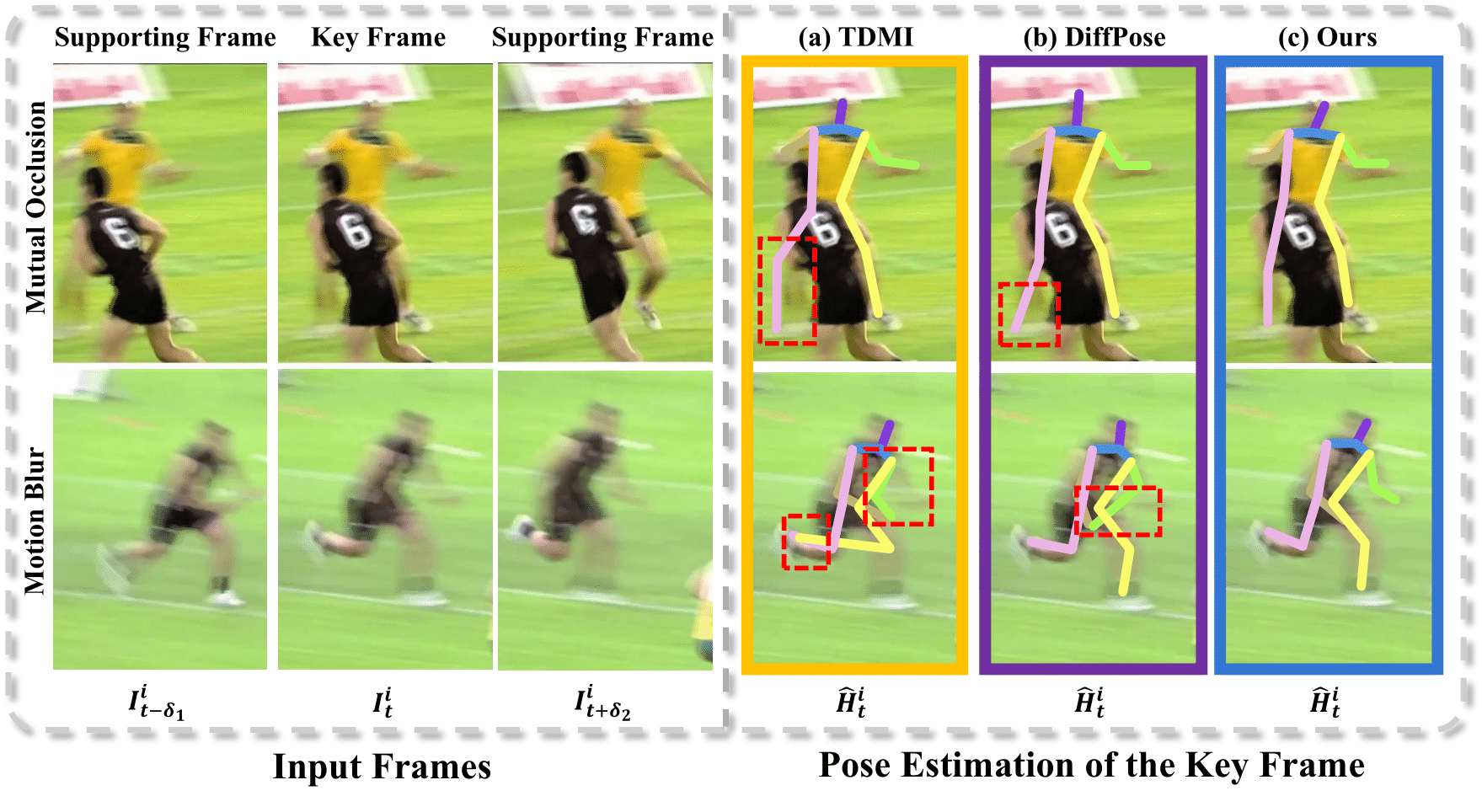
 | Mutual Information-based Temporal Difference Learning for Human Pose Estimation in Video Runyang Feng, Yixing Gao, Xueqing Ma, Tze Ho Elden Tse, Hyung Jin Chang CVPR, 2023 [pdf] [webpage] We present a multi-frame human pose estimation framework, which employs temporal differences across frames to model dynamic contexts. |
 | S$^2$Contact: Graph-based Network for 3D Hand-Object Contact Estimation with Semi-Supervised Learning Tze Ho Elden Tse$^*$, Zhongqun Zhang$^*$, Kwang In Kim, Ales Leonardis, Feng Zheng, Hyung Jin Chang ECCV, 2022 [pdf] [webpage] We propose a semi-supervised framework that learns contact from monocular videos. |
 | Collaborative Learning for Hand and Object Reconstruction with Attention-guided Graph Convolution Tze Ho Elden Tse, Kwang In Kim, Ales Leonardis, Hyung Jin Chang CVPR, 2022 [pdf] [webpage] We propose a collaborative learning framework which jointly reconstructs hand and object from a single RGB image. |
 | TP-AE: Temporally Primed 6D Object Pose Tracking with Auto-Encoders Linfang Zheng, Ales Leonardis, Tze Ho Elden Tse, Nora Horanyi, Wei Zhang, Hua Chen, Hyung Jin Chang ICRA, 2022 [pdf] This paper focuses on instance-level 6D object pose tracking. In particular, the targeted scenarios are symmetric and textureless object under occlusion. |
 | No Need to Scream: Robust Sound-based Speaker Localisation in Challenging Scenarios Tze Ho Elden Tse, D. De Martini and L. Marchegiani ICSR, 2019 [pdf] Master project at Oxford Robotics Institute. |